Scrapy是一个为了爬取网站信息,提取结构性数据而编写的应用框架。Scrapy用途广泛,可用于数据挖掘、监测和自动化测试等。
爬虫执行流程
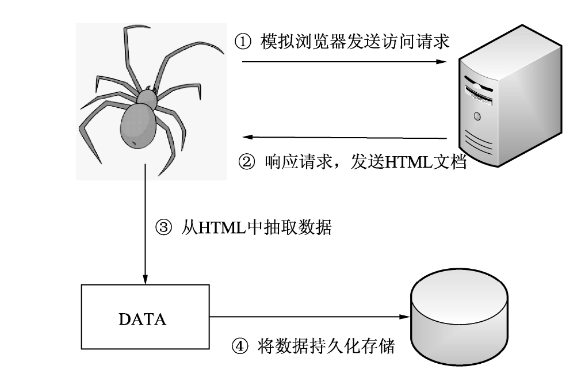
(1)发送请求。爬虫设定一个URL,模拟浏览器使用HTTP协议向网站服务器发送访问请求。
(2)获取HTML文档。服务器接收到请求后,将HTML文档(或者图片、视频等其他资源)发送给爬虫。
(3)抽取数据。爬虫使用XPath或BeautifulSoup从HTML文档中抽取出有用的数据。
(4)保存数据。将抽取到的数据保存到文件(CSV、JSON、TXT等)或数据库(MySQL、MongoDB等)中,实现数据的持久化存储。
Scrapy爬虫执行流程
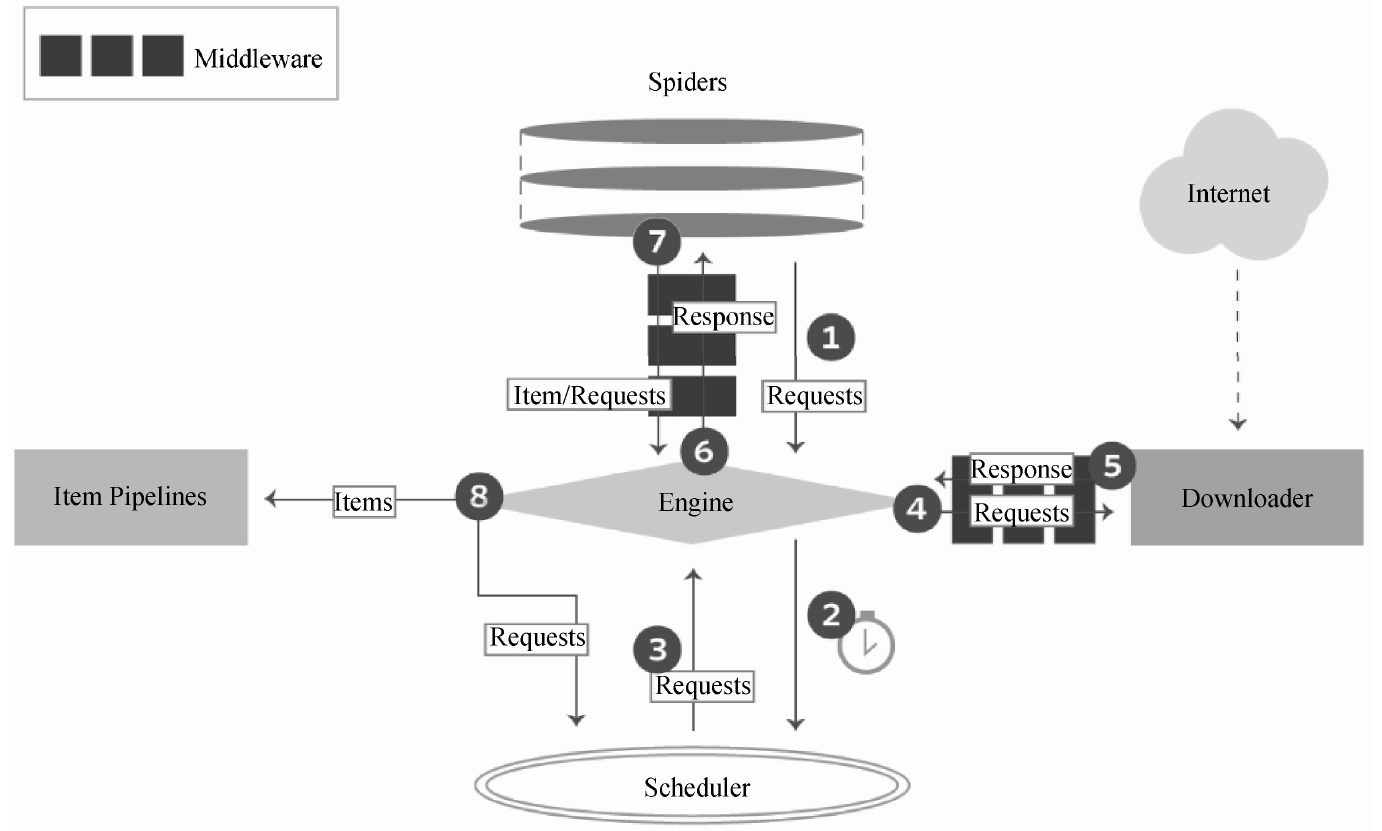
第①、②、③、④步,执行的是HTTP请求,传递和处理的是向网站服务器发送的请求数据。
第①步:爬虫(Spider)使用URL(要爬取页面的网址)构造一个请求(Request)对象,提交给引擎(Engine)。如果请求要伪装成浏览器,或者设置代理IP,可以先在爬虫中间件中设置,再发送给引擎。
第②步:引擎将请求安排给调度器,调度器根据请求的优先级确定执行顺序。
第③步:引擎从调度器获取即将要执行的请求。
第④步:引擎通过下载器中间件,将请求发送给下载器下载页面。第⑤、⑥、⑦、⑧步,执行的是HTTP响应,传递和处理的是网站服务器返回的响应数据。
第⑤步:页面完成下载后,下载器会生成一个响应(Response)对象并将其发送给引擎。下载后的数据会保存于响应对象中。
第⑥步:引擎接收来自下载器的响应对象后,通过爬虫中间件,将其发送给爬虫(Spider)进行处理。
第⑦步:爬虫将抽取到的一条数据实体(Item)和新的请求(如下一页的链接)发送给引擎。
第⑧步:引擎将从爬虫获取到的Item发送给项目管道(Item Pipelines),项目管道实现数据持久化等功能。同时将新的请求发送给调度器,再从第②步开始重复执行,直到调度器中没有更多的请求,引擎关闭该网站。
安装Scrapy
创建虚拟环境
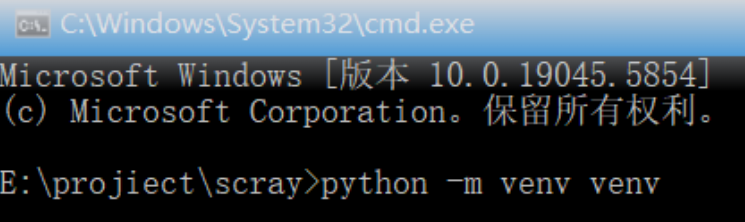
python -m venv venv进入虚拟环境安装scrapy
venv\Scripts\activate.bat
pip install scrapy安装完成
创建Scrapy项目
scrapy startproject scrapypro01
项目结构
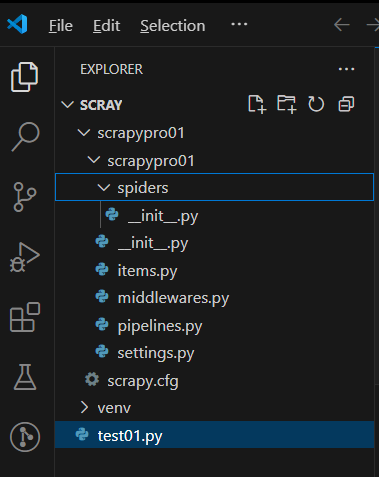
现要获取起点中文网中小说热销榜的数据
(网址为https://www.qidian.com/rank/hotsales?style=1&page=1),每部小说提取内容为:小说名称、作者、类型和形式。
在spiders目录下创建爬虫脚本
#-*-coding:utf-8-*-
from scrapy import Request
from scrapy.spiders import Spider
class HotSalesSpider(Spider):
#定义爬虫名称
name = 'hot'
#起始的URL列表
start_urls = ["https://www.qidian.com/rank/hotsales/page1/"]
#解析函数
def parse(self, response):
#运行后没有爬虫到结果,这里用来打印输出。排查没有爬取到数据的原因
print("_________________________________________________________________________")
print(response)
print("_________________________________________________________________________")
#使用xpath定位到小说内容的div元素,保存到列表中
list_selector = response.xpath("//div[@class='book-mid-info']")
#运行后没有爬虫到结果,这里用来打印输出。排查没有爬取到数据的原因
print("_________________________________________________________________________")
print(list_selector)
print("_________________________________________________________________________")
#依次读取每部小说的元素,从中获取名称、作者、类型和形式
for one_selector in list_selector:
#获取小说名称
name = one_selector.xpath("h4/a/text()").extract()[0]
#获取作者
author = one_selector.xpath("p[1]/a[1]/text()").extract()[0]
#获取类型
type = one_selector.xpath("p[1]/a[2]/text()").extract()[0]
#获取形式(连载/完本)
form = one_selector.xpath("p[1]/span/text()").extract()[0]
#将爬取到的一部小说保存到字典中
hot_dict = {"name":name, #小说名称
"author":author, #作者
"type":type, #类型
"form":form} #形式
#使用yield返回字典
yield hot_dict运行爬虫

运行后响应为202,

202的原因:
-
202状态码表示请求已被接受但未处理完成,目标网站可能通过异步验证(如反爬机制)拦截了请求。
-
可能触发了反爬策略(如请求头异常、频率限制)。
尝试解决:
1、伪装成真实浏览器发送请求:
-
打开开发者工具
-
快捷键:
F12或Ctrl+Shift+I(Windows/Linux);Cmd+Opt+I(Mac)。 -
右键点击页面空白处,选择“检查”。
-
-
切换到Network(网络)面板
-
在开发者工具顶部标签栏中点击 Network。
-
-
捕获请求
-
刷新页面(
F5或Ctrl+R),所有网络请求会显示在列表中。 -
若需捕获动态加载的请求(如点击按钮触发的API),先打开Network面板再操作页面。
-
-
查看请求头
-
点击任意请求名称 → 选择 Headers 标签 → 展开 Request Headers 部分。
-
关键字段包括:
-
User-Agent:浏览器标识 -
Cookie:会话信息 -
Accept/Accept-Language:内容协商 -
Referer:来源页面
-
-
setting.py中添加如下信息:
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0',
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en",
}
最终还是没解决202问题。
解决方法二:
动态内容:用Splash渲染
1、安装Splash
pip install scrapy-splash
2、配置Splash 服务
拉取镜像:docker pull scrapinghub/splash
运行Splash容器:docker run -d -p 8050:8050 scrapinghub/splash
3、配置Scrapy项目:在Scrapy项目的settings.py文件中,需要添加一些配置来启用Splash中间件和设置Splash服务器地址
SPLASH_URL = 'http://47.108.62.29:8050' # 如果Splash运行在本地的默认端口
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
4、重写函数
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url, args={'wait': 2}, callback=self.parse) # 等待2秒渲染
#再次运行爬虫
scrapy crawl hot -o hot2.csv最终响应成功,但是出现了,list_selector为空
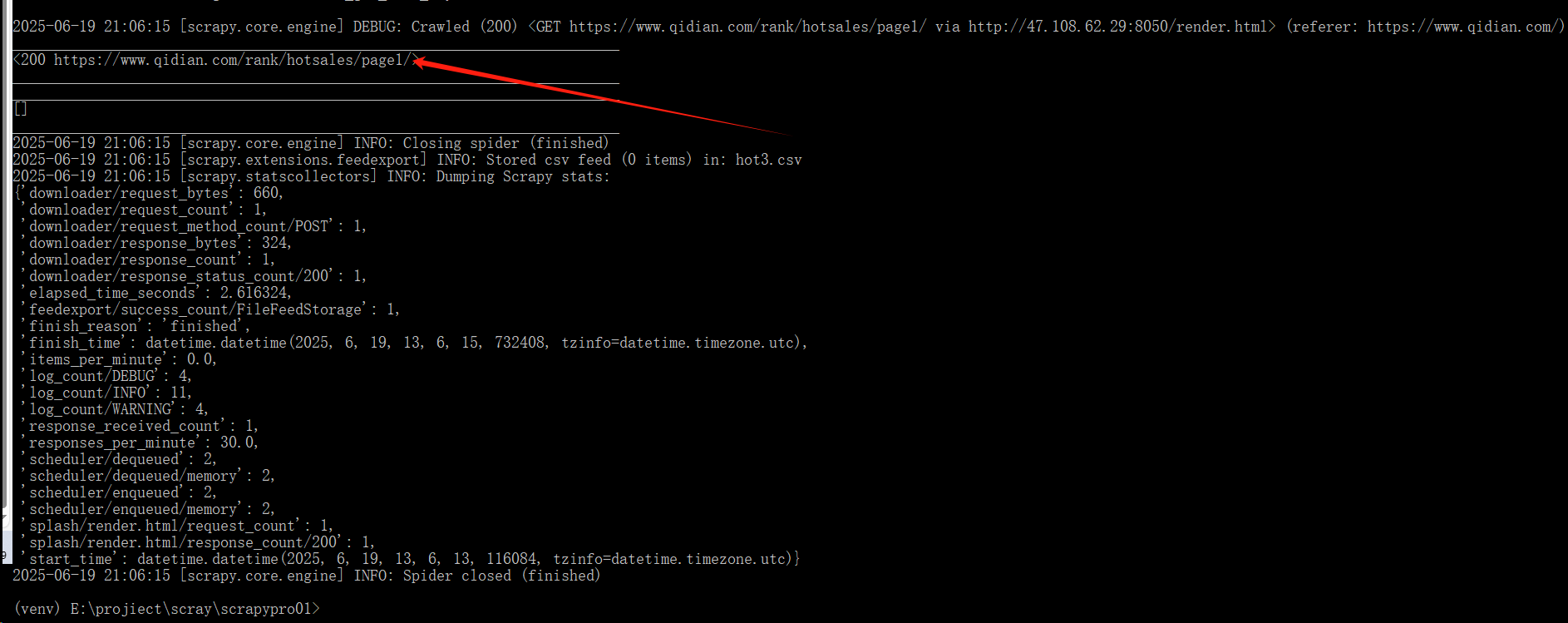
再次排查:将响应内容写入html文件。
# 保存渲染后的HTML到文件(调试用)
with open("debug.html", "w", encoding="utf-8") as f:
f.write(response.text)发现html内容如下,为空。根本就没有小说内容:
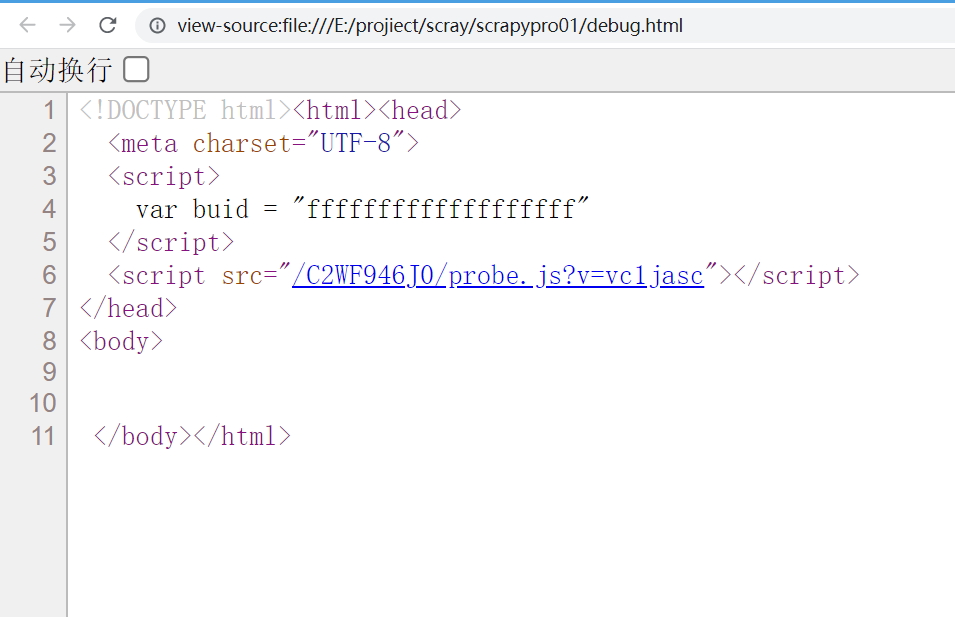
再次优化请求函数如下:
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
callback=self.parse,
args={
"wait": 5, # 延长至5秒(原2秒不足)
"lua_source": """
function main(splash)
splash:go(splash.args.url)
splash:wait(5) -- 二次等待确保加载
return splash:html()
end
"""
}
)最终还是不行。